Homem usando o PC | Foto: Ilustrativa / LensGo
[Foto: Ilustrativa / LensGO]
O Chief Technology Officer (CTO) da Cloudflare, Dane Knecht, manifestou-se publicamente nesta terça-feira para confirmar e explicar uma falha significativa que afetou a rede da empresa e, consequentemente, uma vasta quantidade de tráfego na internet. Em comunicados emitidos em sua rede social, o executivo admitiu que a empresa “falhou com seus clientes e com a internet em geral” devido a um problema técnico que impactou sites, empresas e organizações que dependem da disponibilidade dos serviços da Cloudflare. Knecht pediu desculpas pelo impacto causado, esclareceu a natureza técnica do incidente e forneceu atualizações sobre o processo de restabelecimento das operações e da plataforma de controle.
Admissão da falha e pedido de desculpas
O posicionamento do CTO ocorreu por volta do meio-dia (horário de Brasília), momento em que ele abordou a situação de forma direta. Knecht afirmou que não mediria palavras para descrever a gravidade do ocorrido. Segundo ele, a confiança depositada pelos clientes é o valor mais importante para a companhia, e o episódio de hoje representou uma quebra nessa expectativa de disponibilidade.
O executivo reconheceu explicitamente que o problema causou “dor real” aos usuários e classificou tanto o incidente quanto o tempo levado para a resolução como inaceitáveis. A declaração inicial focou em assumir a responsabilidade pelo impacto gerado na rede, reforçando que as organizações que utilizam a infraestrutura da Cloudflare dependem dela para se manterem online e operacionais.
Causa técnica: Configuração de rotina e Bug Latente
Em nome da transparência sobre o que de fato aconteceu, Dane Knecht forneceu uma explicação preliminar sobre a raiz do problema, descartando imediatamente a hipótese de uma ação maliciosa externa. O CTO foi categórico ao afirmar: “Isso não foi um ataque”.
De acordo com as informações técnicas divulgadas, o problema originou-se de uma mudança de configuração de rotina realizada pela equipe. Essa alteração, no entanto, ativou um “bug latente” presente em um serviço específico que sustenta a capacidade de mitigação de bots da empresa. O acionamento desse erro de software fez com que o serviço começasse a falhar (crash), o que desencadeou um efeito cascata. Esse efeito resultou em uma ampla degradação da rede e afetou outros serviços da companhia, gerando a instabilidade percebida por diversos setores da internet que utilizam a infraestrutura da Cloudflare.
Cronograma de recuperação e o “Control Plane”
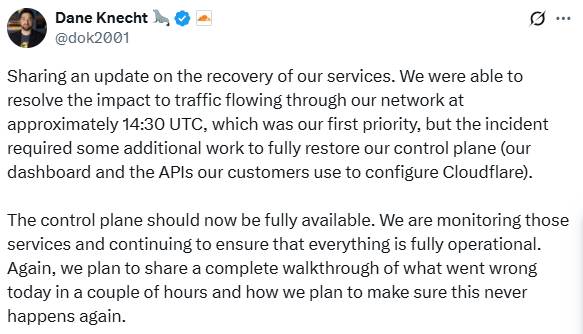
Cerca de duas horas após a primeira comunicação, o CTO publicou uma atualização detalhando o andamento da recuperação dos serviços. Segundo Knecht, a prioridade inicial da equipe foi resolver o impacto no tráfego que flui através da rede da Cloudflare. Essa etapa crítica da recuperação foi concluída aproximadamente às 14h30 UTC.
No entanto, o executivo explicou que, mesmo após a normalização do fluxo de tráfego, o incidente exigiu trabalhos adicionais para a restauração completa do chamado “plano de controle” (control plane). Conforme definido por Knecht em sua publicação, o plano de controle engloba o painel de controle (dashboard) e as APIs que os clientes utilizam para configurar os serviços da Cloudflare.
Na segunda atualização, foi informado que esse plano de controle já deveria estar totalmente disponível. As equipes técnicas continuam monitorando os serviços para assegurar que tudo permaneça totalmente operacional após as correções aplicadas.
Promessa de transparência e relatório completo
O executivo da Cloudflare reiterou o compromisso da empresa com a transparência. Ele informou que um relatório detalhado (“breakdown” ou “walkthrough”) sobre o incidente será compartilhado em algumas horas. Esse documento deverá conter uma análise completa do que deu errado durante o dia de hoje.
Além de explicar as falhas, o relatório futuro e as ações atuais da empresa têm como objetivo demonstrar os planos para garantir que esse tipo de problema não volte a ocorrer. Knecht enfatizou que o trabalho para prevenir a reincidência da falha já está em andamento e que a empresa fará o que for necessário para reconquistar a confiança de seus clientes.
Confira, a seguir, as publicações do CTO: